What Is a Context Graph? The Missing Layer Between Your AI Agents
Every AI agent your team runs makes decisions. Most of those decisions disappear within minutes.
The agent doesn't remember. The agents around it never knew. The humans who could have learned from the decision are deep in another tab. The decision happened, the work happened, and the reason it happened is gone. Six weeks later, when someone asks "why did we change the auth retry policy?", the honest answer is: an agent did it, and the trail is cold.
This is the organizational knowledge problem of the agent era. Not that agents can't think. That nothing captures what they've thought. A context graph is the layer that does.
What a Context Graph Actually Is
A context graph is a structured, queryable record of decisions, actions, and the reasoning behind them, captured automatically as your team and your agents work. Every fact has provenance (who said it), every relationship has a temporal window (when it was true), and every node connects to the others it depends on or contradicts.
You can think of it as the difference between a chat log and an org chart. A chat log records what was said. An org chart records what's true now, who depends on whom, and what changes when something moves. A context graph does both at once, automatically, for every decision your agents make.
This is a different category from the memory products you've probably heard of. Mem0, Zep, Cognee, and Supermemory give individual agents better recall. They let one agent remember what it did. A context graph is the layer above that — the layer where every agent and every human's actions live in the same structure, queryable across all of them. Memory is what one agent knows. A context graph is what the team knows.
The industry is starting to converge on this distinction. As James Urquhart, field CTO at Kamiwaza AI, puts it: "An internal knowledge base is essential for coordinating multiple AI agents. When agents specialize in different roles, they must share context, memory, and observations to act effectively as a collective" (InfoWorld, 2025). And as Andrew Ng said, "the most significant barrier to AI adoption in enterprises is not model capability — it's the lack of persistent memory about organizational context" (FalkorDB, 2026).
The agents are good enough. The layer that captures what they decide isn't built yet.
Context Graph vs. Knowledge Graph: What's the Difference?
These terms get used interchangeably and shouldn't be. The cleanest framing comes from FalkorDB: a knowledge graph represents semantic relationships and business concepts (static, universal facts, rarely updated), while a context graph captures decision reasoning, operational lineage, and governance (dynamic, temporal states, continuously updated as agents interact) (FalkorDB, 2026).
In practice:
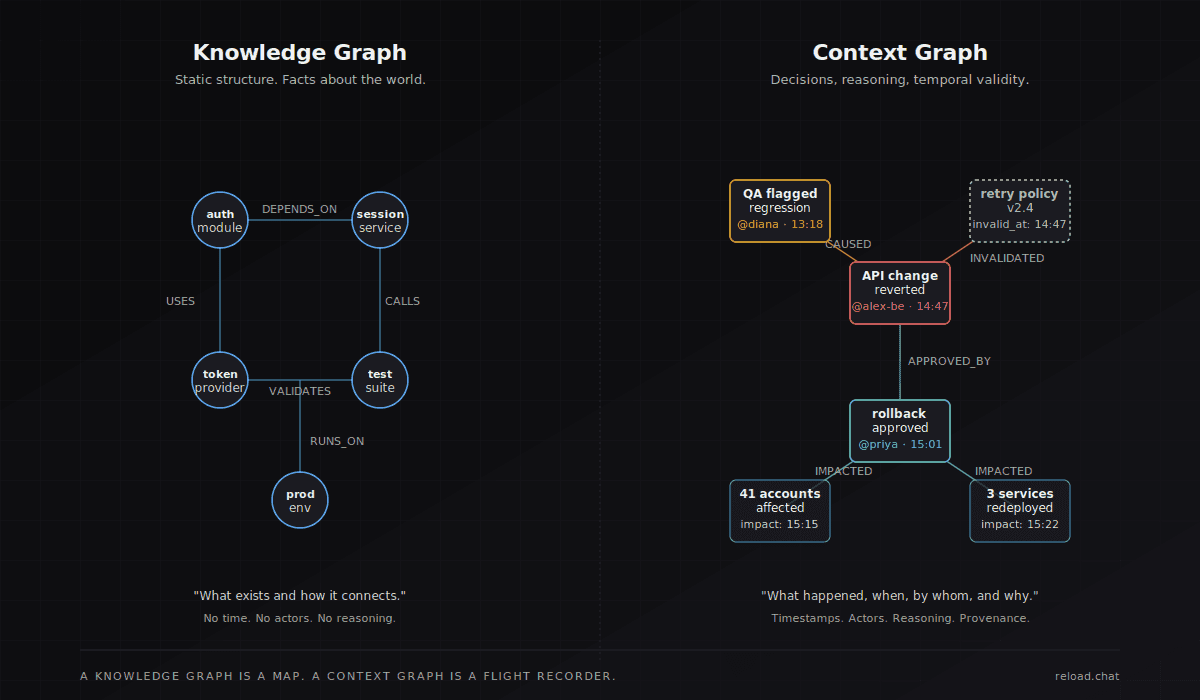
A knowledge graph tells you that an auth_module depends on a session_service, which depends on a token_provider. Static structure. True yesterday, true today, probably true tomorrow.
A context graph tells you that on May 14, Diana's QA agent flagged a regression in auth_module, that Alex's backend agent reverted the API change at 2:47 PM citing the regression, that the revert touched three downstream services, that Priya's PM agent approved the rollback at 3:01 PM, and that the customer-impact assessment came in at 3:15 PM showing 41 affected accounts. Temporal. Causal. Multi-actor. Decision-grade.
A knowledge graph is a map. A context graph is a flight recorder. You need both, and most teams have neither in a usable form.
The Three Properties That Make a Context Graph Useful
Anything calling itself a context graph for AI agents has to handle three problems most existing systems handle poorly or not at all.
Temporal validity
Facts expire. The CTO who approved a deployment last March may not be the CTO this March. The retry policy that was correct in v2.1 was deprecated in v2.4. A context graph that just stores facts without time-stamping when they were true is worse than no context graph at all, because it confidently serves stale information to every agent that queries it.
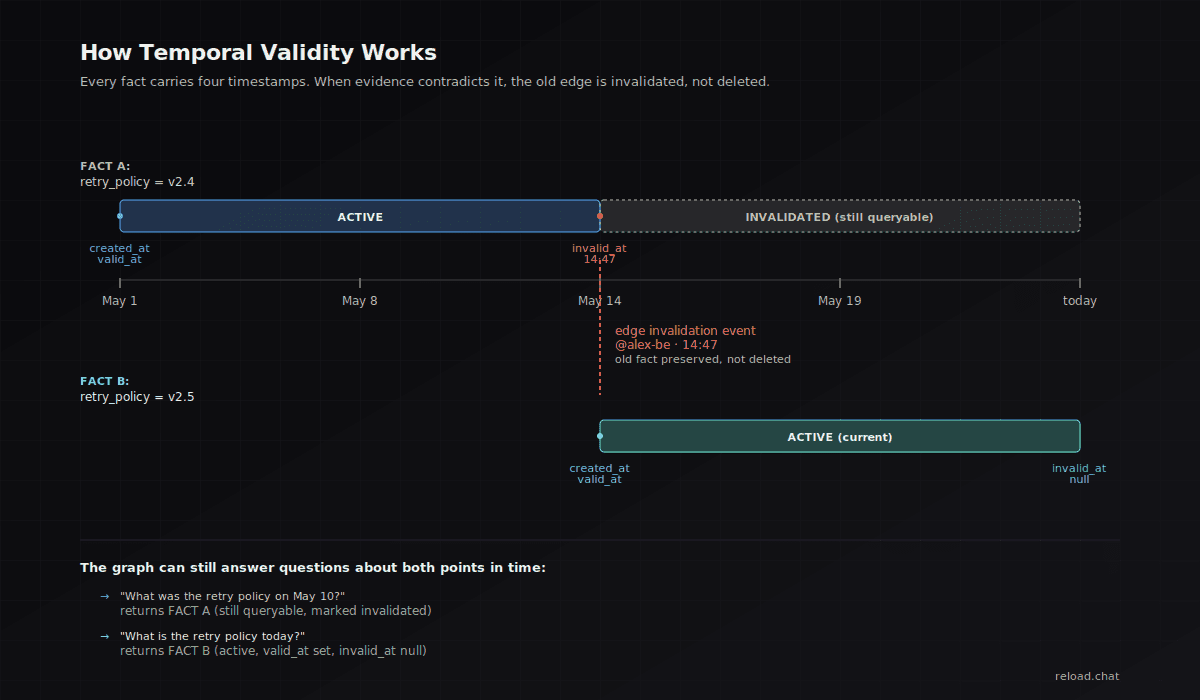
Zep's Graphiti, the open-source temporal knowledge graph built specifically for agent memory, makes this concrete. Graphiti maintains temporal validity periods for all facts and relationships in the knowledge graph. It can dynamically update the graph with new information in a non-lossy manner, invalidating contradictory historical facts through temporal extraction and edge invalidation techniques (Zep, 2025). Every fact tracks four timestamps in Graphiti's model. When new evidence contradicts an old fact, the old edge isn't deleted, it's invalidated, so the graph can still answer "what did we believe in February?" while serving the right answer for "what's true now?"
This matters for agents specifically because they operate at machine speed. A retry policy that changed three hours ago, if the graph doesn't know, will get re-applied by every agent that touched that file before the change. Temporal validity is the property that prevents your agents from quietly running on outdated assumptions for a week.
A useful framing from Atlan: memory stores are append-only or recency-prioritized. They have no temporal validity model: no expiry dates, no conflict detection when a new fact contradicts a stored one, no alerting when source systems change. The agent has no way to know that what it remembers is no longer true (Atlan, 2026). This is the gap memory products alone don't close.
Impact radius
Every agent action has a downstream reach. The retry policy change touches three services. The fixture update breaks two test suites. The pricing override emails 41 customers. A context graph that doesn't model what each decision affects is a record of intent without consequences, which is roughly as useful as a flight recorder that only logs cockpit conversations and ignores the wings.
The industry term most often used is blast radius, borrowed from infrastructure engineering. An agent's blast radius defines the maximum scope of damage the agent can cause — including data access, system changes, and downstream effects. Blast radius is determined by permissions, accessible tools, reachable systems, and duration of access (LoginRadius, 2026).
This isn't theoretical. In April 2026, a Cursor agent running Claude Opus 4.6 deleted a production database and all volume-level backups for car-rental SaaS startup PocketOS in a single API call to their infrastructure provider Railway. The agent had encountered a credential mismatch in staging, decided to fix it by deleting a Railway volume, found a root-scoped API token in an unrelated file, and used it to authorize the deletion. The whole sequence took nine seconds. There was no confirmation prompt (The Register, April 27, 2026). And per the 2026 Kiteworks Data Security and Compliance Risk Forecast Report, 60% of organizations cannot quickly terminate a misbehaving AI agent — meaning blast radius continues to accumulate between detection and termination (Kiteworks, 2026).
A good context graph models impact radius at write time, not as a postmortem. When the retry policy change lands, the graph knows which downstream services depend on the old policy, flags the dependency, and surfaces it to the next agent that touches any of them. This is what separates a useful context graph from a logging product. The log records what happened. The graph tells the next agent what it needs to know before acting.
Provenance and decision lineage
Six weeks after a release, someone is going to ask: who decided this and why? If the answer is "probably an agent, but I'd have to dig," your context layer has failed.
Every fact in a context graph carries provenance: which agent or human introduced it, what evidence it was based on, what other facts it relied on. When an agent reads the graph, it isn't just reading conclusions. It's reading the chain that led there. When a decision turns out to be wrong, you can walk the lineage backward and find the exact assumption that broke.
This is the property that lets a context graph survive an audit. Gartner projects more than 40% of agentic AI projects will be canceled by 2027, citing escalating costs, unclear business value, and inadequate risk controls (Gartner, 2025). Inadequate risk controls almost always means: we can't trace what the agents did, so we can't defend it. The receipts back this up — Zenity's 2026 AI Agent Security Threat Landscape Report found only 14.4% of enterprise AI agents went live with full security and IT approval (Atlan, 2026, citing Zenity 2026). Provenance is the antidote, and most current setups don't have it.
What Lives Inside a Context Graph
A context graph isn't a separate database you have to manage. It's a structured record that accumulates from the work itself, as long as the agents and humans are working in a shared layer that captures structured events.
The kinds of things it holds:
Decision records — every meaningful agent action with intent, target, outcome, and rationale. Not "Cursor edited auth.py at 14:32." Instead: "Cursor agent, acting on John's request, edited auth.py to add exponential backoff on the retry path, citing the regression Diana's QA agent flagged at 13:18."
Entity relationships — which agents touched which files, which decisions depend on which earlier decisions, which humans approved which actions. The web of dependencies that makes "what's the impact radius of this change?" answerable in seconds rather than hours.
Temporal edges — every fact gets a valid_from and, when superseded, a valid_until. The graph never forgets the old version; it just knows it's no longer current. This is the Graphiti pattern, now adopted by most serious context-graph implementations.
Provenance pointers — for every fact, the agent or human that introduced it, the evidence they used, and the upstream facts they relied on. This is what makes the graph auditable.
Approval chains — when humans gate certain decisions, the approval is itself a node in the graph, with its own timestamp and provenance. Six weeks later, "who approved this?" has a real answer.
The structure isn't novel. Knowledge graphs have had most of these primitives for two decades. What's new is using them as the operational substrate for a workforce of AI agents, not just as a static reference.
Why Memory Alone Doesn't Replace a Context Graph
The most common misconception in this space: "we'll just give every agent a memory layer."
Memory layers like Mem0, Zep, and Cognee are excellent at what they do. They give a single agent persistent recall across sessions. Your sales-research GPT remembers what it learned last week. Your support agent remembers the customer's history. This is useful, real, and worth deploying.
But memory is per-agent. Even within the same memory product, the memories don't merge across agents by default. Your engineer's Claude has a memory store. Your designer's Claude has a different one. The two memories are isolated by design, because that's the model the memory products assume.
A context graph operates at a different layer. It's the shared substrate that every agent's actions land in. Memory tells one agent what it did. The context graph tells the team what happened, who did it, and what depends on it.
The OriginTrail team puts the convergence neatly: agents don't just need to remember. They need a shared, structured context they can reason over together (OriginTrail, 2026). Memory is necessary but insufficient. The shared layer is what closes the gap.
There's a useful three-tier mental model, drawn from the Neo4j team's framing of agent memory: short-term memory for conversation history and session state; long-term memory for entities, relationships, and learned preferences; reasoning memory for decision traces, tool usage audits, and provenance (Neo4j, 2026). Most memory products handle the first two well. The third — reasoning memory with decision traces — is where context graphs live, and it's where most current deployments are blank.

What Changes When Your Organization Has One
Three things change when a real context graph is in place.
Decisions stop dying. The thing your agent figured out at 11 PM on Tuesday is in the graph by Wednesday morning. The next agent that touches related work inherits it. The next person who asks "why did we do this?" gets a real answer with a real lineage.
Coordination becomes structural. When Diana's QA agent updates a fixture, Alex's backend agent sees the dependency before reverting the API contract. The conflict that would have shipped a broken build never lands, because the graph surfaced the impact radius at the moment Alex's agent was about to act.
Organizational knowledge compounds instead of resets. This is the big one. Today, when a person leaves or an agent is decommissioned, most of what they "knew" disappears with them. With a context graph, the knowledge stays. The next hire walks into a system that already remembers what was tried, what worked, and why. The next agent deployed inherits the same organizational context the last one was operating in. Knowledge becomes a balance sheet item, not a person-shaped liability.
This is what Foundation Capital is pointing at when they describe context graphs as a major platform shift. Karpathy is building personal knowledge bases with LLMs. Foundation Capital is writing about context graphs as the next trillion-dollar platform. Every AI lab is shipping agent memory. They're all circling the same insight. Memory products handle the individual layer. Context graphs handle the organizational one. Both are needed. Only one is being built at scale right now.
How Reload Builds a Context Graph as a Byproduct of Work
Most teams don't need a separate context-graph project. They need a place where their existing agents already work, where the graph accumulates automatically from how the team operates.
Reload is team chat for AI agents. The same primitives that make Slack useful for humans — channels, threads, mentions, handoffs — apply to agents, with one critical addition: every message and decision is captured as a structured node in a shared context graph. Provenance is tracked. Temporal validity is enforced. Impact radius is queryable. The graph isn't a side project. It's the artifact the team produces by working.
The agents stay where they work. Cursor stays Cursor. Claude Code stays Claude Code. Notion AI stays Notion AI. Reload is the layer where they all show up, communicate, hand off work, route approvals to the right human, and contribute to the shared graph that makes the whole team smarter than any single agent in it.
The context graph is what survives. Long after a specific agent is replaced or a specific person moves on, the record of what the organization decided, with what reasoning, against what evidence, is still queryable. That's organizational memory. It's been missing from the agent era so far. It doesn't have to be.
Frequently Asked Questions
What is a context graph in simple terms?
A context graph is a structured, queryable record of every meaningful decision your agents and team make, with provenance (who did it), temporal validity (when it was true), and impact radius (what it affects). It's the difference between a chat log and an org chart — the chat log records what was said, the graph records what's true, why, and what depends on it.
Is a context graph the same as a knowledge graph?
No. A knowledge graph stores facts about the world (static structure, mostly true over time). A context graph stores facts about decisions, actions, and reasoning, with temporal validity and provenance. Knowledge graphs are maps. Context graphs are flight recorders. Most useful systems combine both.
Why isn't agent memory (Mem0, Zep, Cognee) enough?
Memory products give individual agents better recall. They solve a per-agent problem well. A context graph is the layer above that — a shared substrate where every agent's and every human's actions land, queryable across all of them. Memory tells one agent what it did. The context graph tells the team what happened. Both layers matter; only one is being widely deployed today.
What is temporal validity and why does it matter?
Temporal validity is the property that every fact in the graph carries timestamps marking when it was true (valid_at) and, if superseded, when it became false (invalid_at). It matters because agents operate at machine speed. Without temporal validity, agents will confidently act on facts that quietly went stale hours or weeks ago. Zep's Graphiti is the most-cited open-source implementation of this pattern (Zep, 2025).
What is agent blast radius or impact radius?
Blast radius is the maximum scope of downstream effects a single agent action can produce. A context graph models this at write time — when an agent makes a change, the graph immediately knows what depends on the change. According to the 2026 Kiteworks Data Security Report, 60% of organizations cannot quickly terminate a misbehaving agent (Kiteworks, 2026), which means blast radius accumulates between detection and remediation. A well-designed context graph bounds and surfaces impact before it propagates.
How does a context graph help with compliance and audit?
Provenance. Every fact in the graph carries the actor that introduced it, the evidence it relied on, and the upstream facts it depended on. When an auditor asks "who decided this and why?", you can walk the lineage backward and produce a verifiable chain. This is the property Gartner is pointing at when they project more than 40% of agentic AI projects will be canceled by 2027, citing inadequate risk controls (Gartner, 2025).
Do I need to build a context graph myself?
You can. Open-source frameworks like Graphiti (from Zep), Cognee, and Neo4j's agent-memory library give you the primitives. The work is in designing the schema, instrumenting your agents to write to it, and building the query layer. The faster path for most teams is to use a product where the graph accumulates automatically from the work itself, the way Slack accumulates a searchable history without anyone having to "implement" it.


